What is Association Rule Mining?
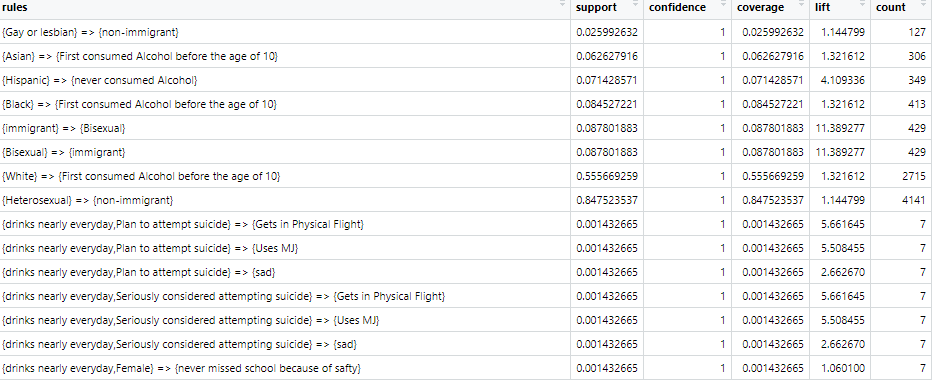
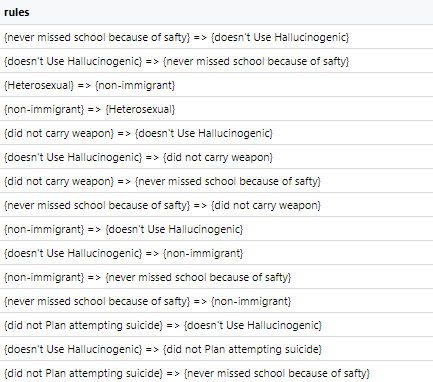
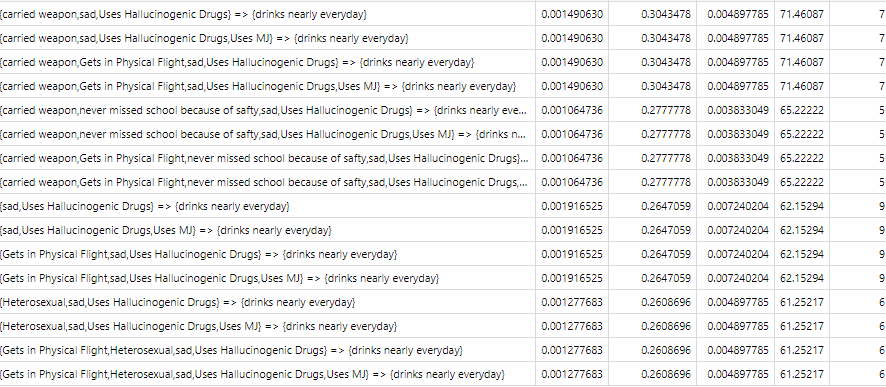
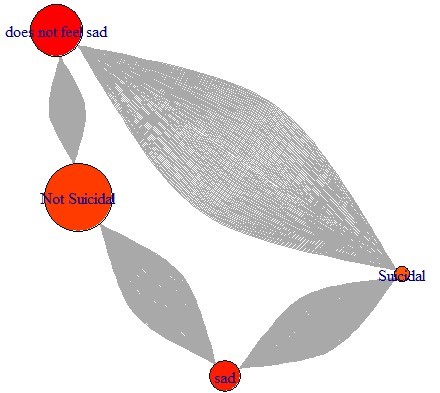
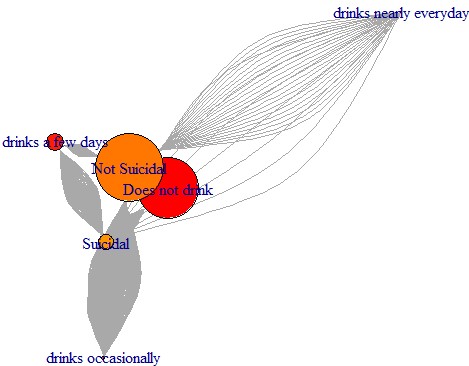
Association Rule Mining, known as ARM, is a machine learning method often used to discover relationships between variables in a given transaction dataset. Each row contains categorical variables within a single observation. ARM evaluates which variables in the dataset are most likely to occur together. ARM using the Apriori algorithm is performed to discover the relationship between items in our dataset. The Apriori algorithm allows us to see general trends in our dataset based on three different measures of probability: confidence, support, and lift. This analysis seeks the relationship between categorical variables based on survey responses from 10,000 individuals. Notably, this analysis is interested in what variables are contributing factors that lead to attempts of suicide among teens.
Association Rule Mining in R
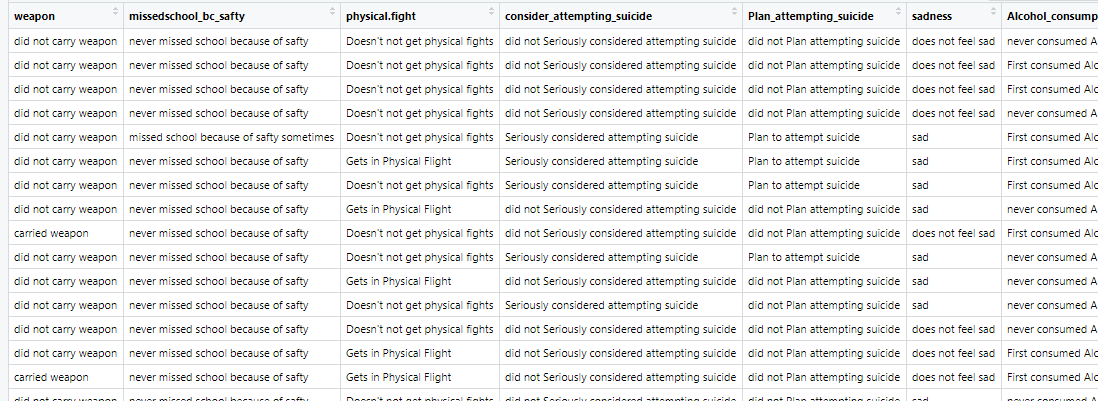
Preparing Transaction Data:The YRBSS data is used for this analysis. The data contains demographic variables including gender, race, sexual orientation. It also has categorical variables that tell us whether one carries a weapon, gets in physical fights, feelings of sadness, whether one has considered attempting suicide, whether one has made plans to attempt suicide, and more
Figure 1:Youth Risk Behavior Surveillance System (YRBSS) Data Ssed for ARM and Networking
Link to dataset: transaction dataset.