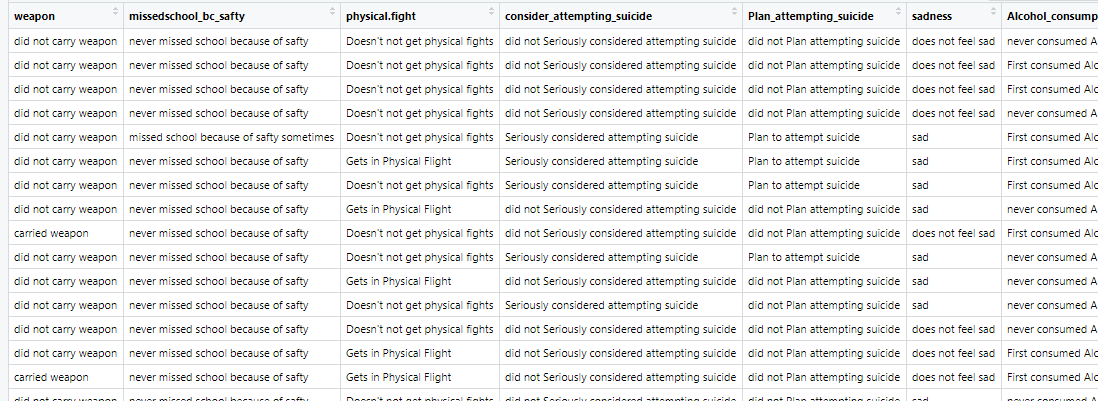
Creating Decision Trees
Upon the creation of the final cleaned datased , decision tree is able to be prefomed. The code used to perform the decision tree can be found here: Code for creating decision three.
|
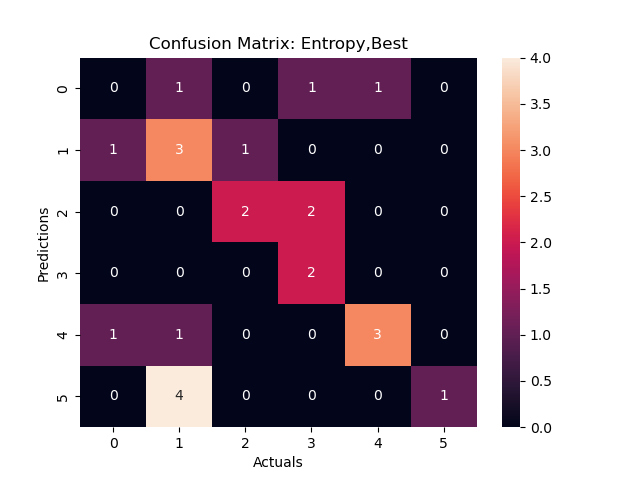
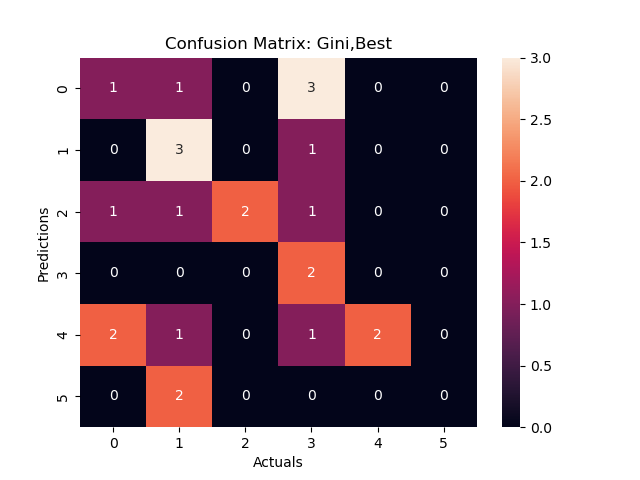
Figure 2a:Confusion Matrix 1
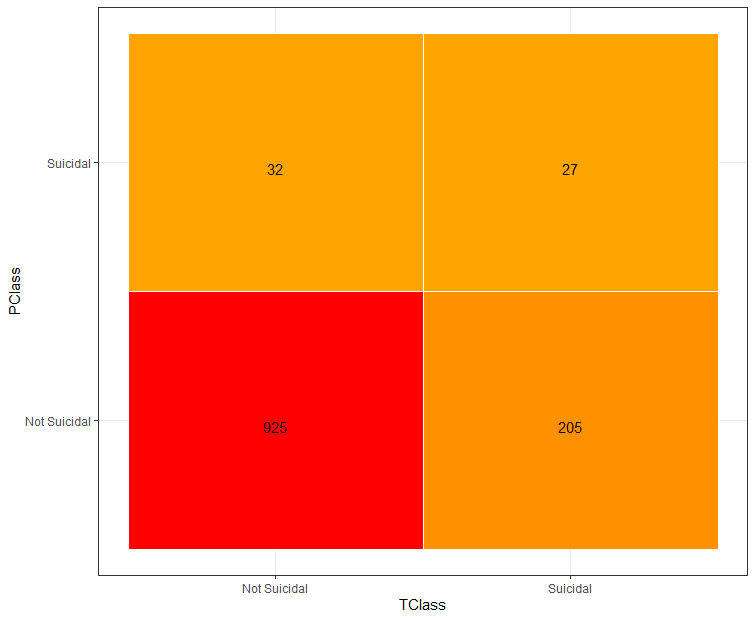
|
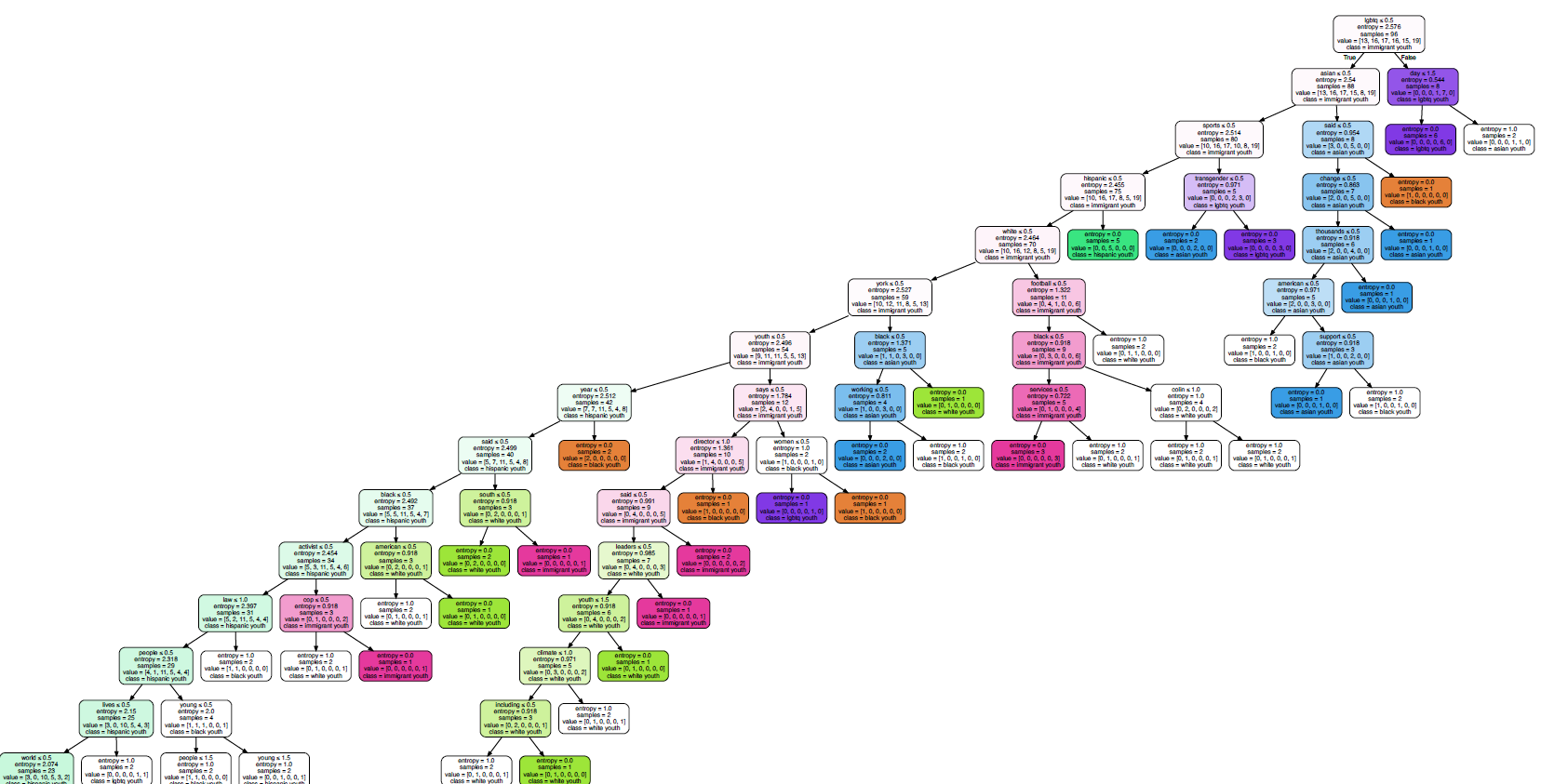
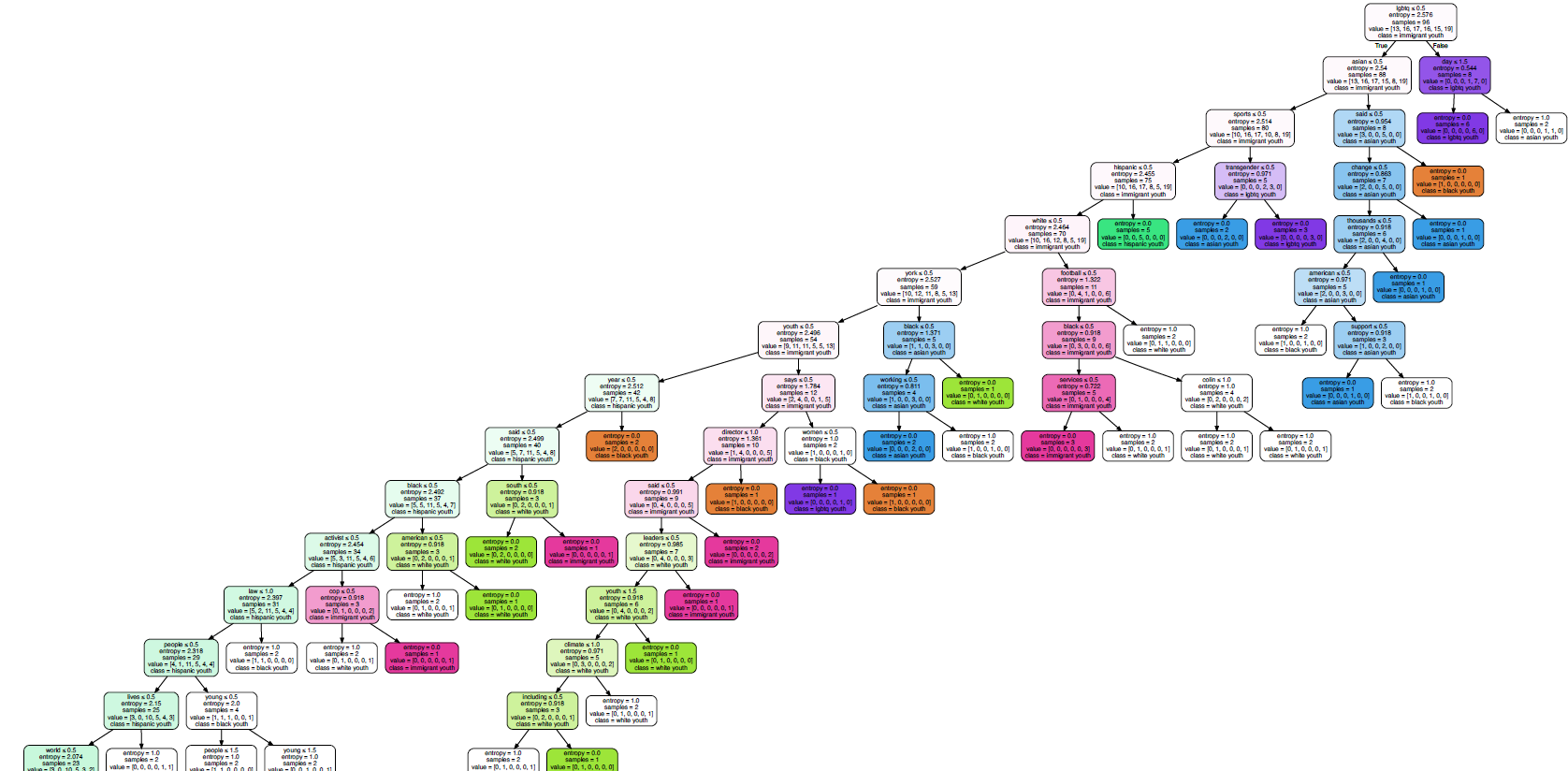
Figure 2b:Decision Tree 1
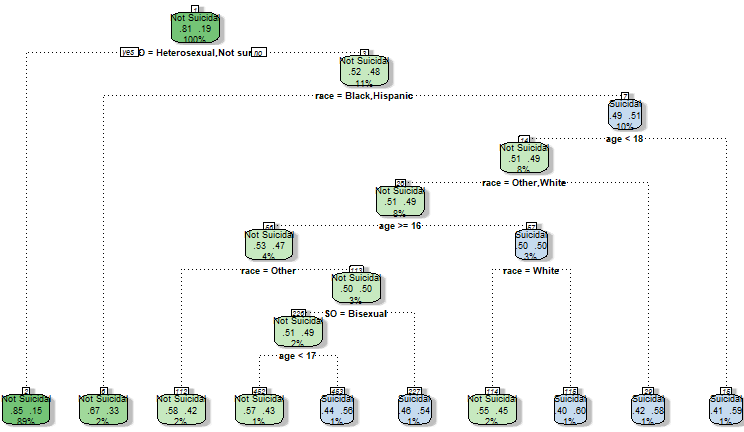
|
Using the variable "considered attempting Suicide" as the root node , this decision tree looked at how different racial, age and sexual identities interact with whether one has considered suicide or not. Based on this decision tree above, we can see that large portion (89%) of those who identified as Heterosexual or "not sure" did not considered attempting suicide. When we look at youth who identified as Bi, Gay or Lesbian, race was an important factor on whether they have considered attempting suicide or Race. Specifically, those who are Black and/or Hispanic were likely to consider attempting suicide.
|
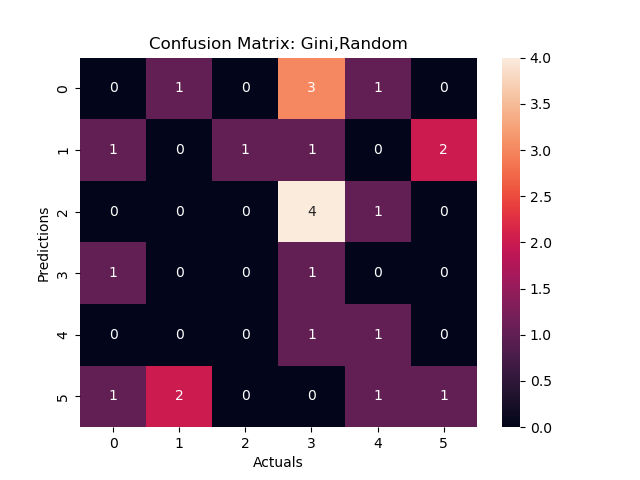
Figure 3a:Confusion Matrix 2
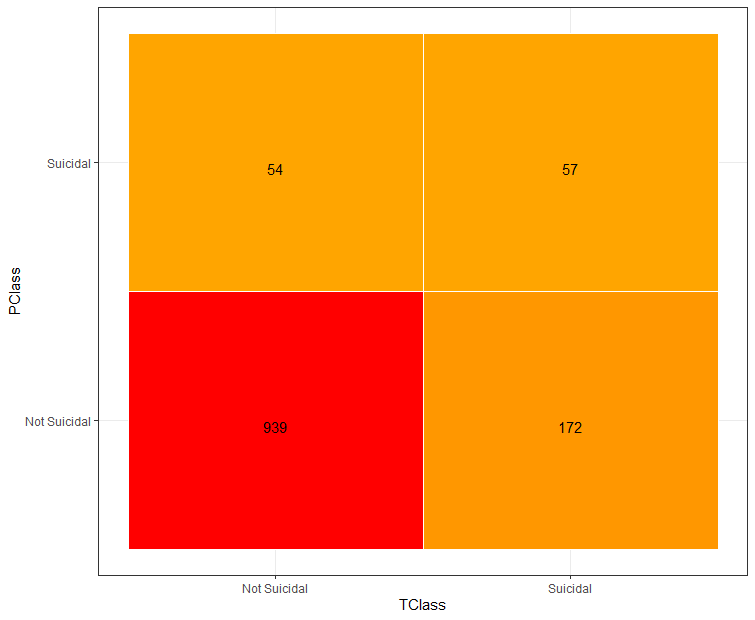
|
Figure 3b:Decision Tree 2
|
Using the variable "considered attempting Suicide" as the root node , this decision tree looked at how different racial, age and sexual identities interact with whether one has considered suicide or not. Based on this decision tree above, we can see that large portion (89%) of those who identified as Heterosexual or "not sure" did not considered attempting suicide. When we look at youth who identified as Bi, Gay or Lesbian, race was an important factor on whether they have considered attempting suicide or Race. Specifically, those who are Black and/or Hispanic were likely to consider attempting suicide.
Figure 4a:Confusion Matrix 1
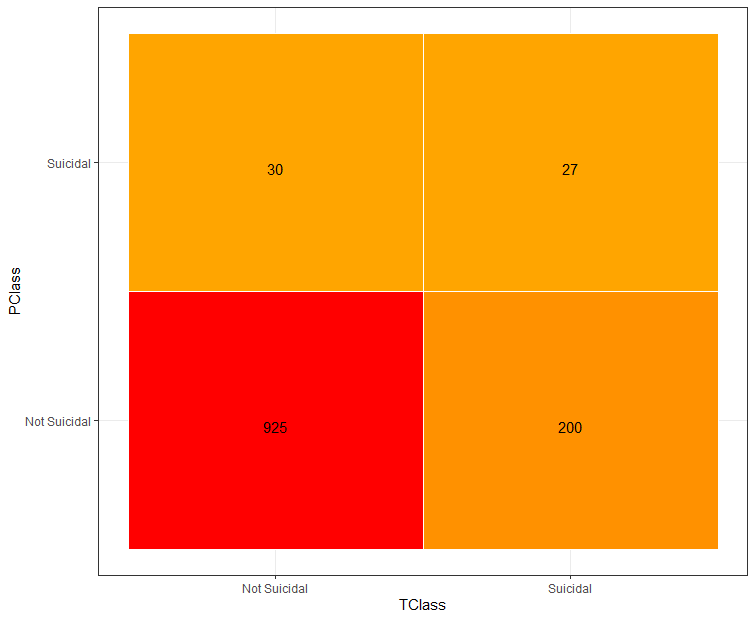
|
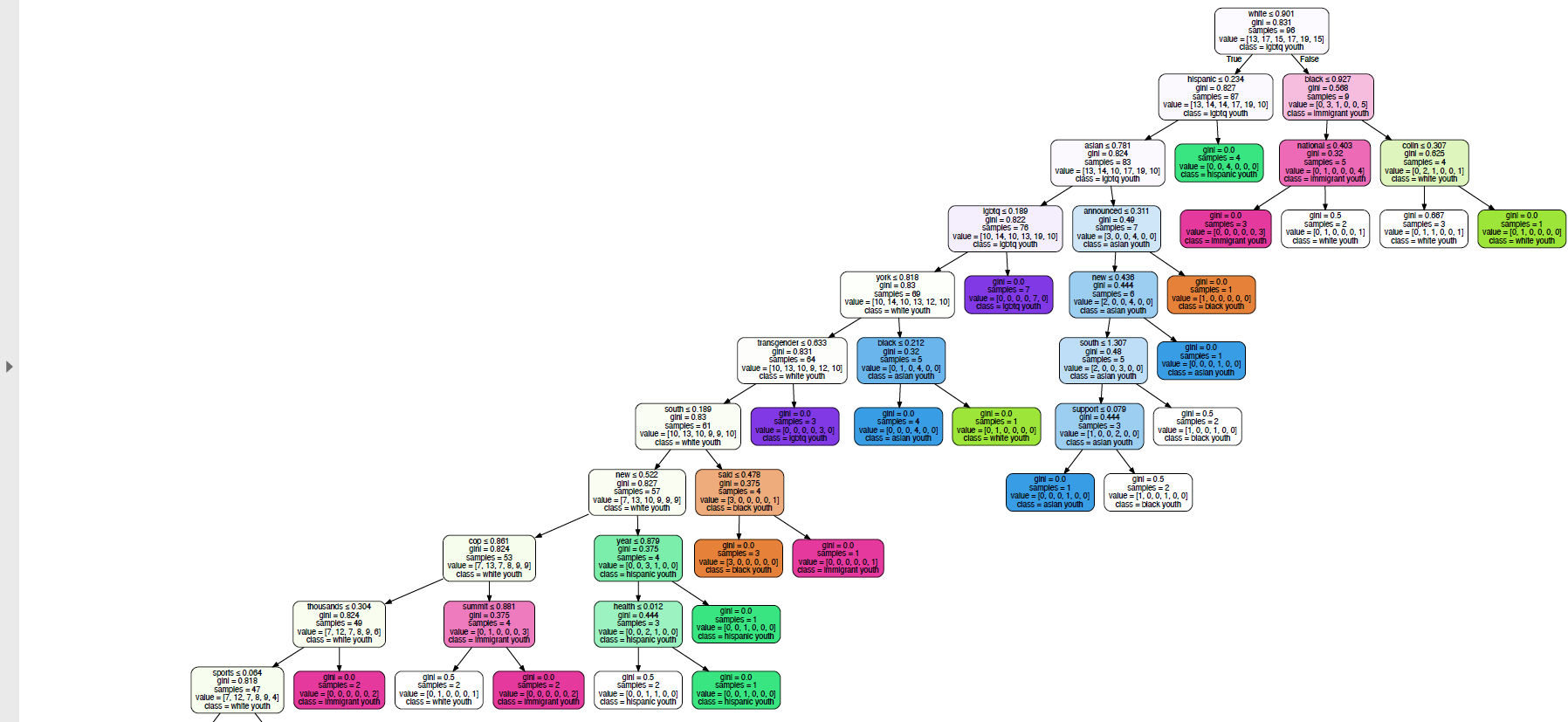
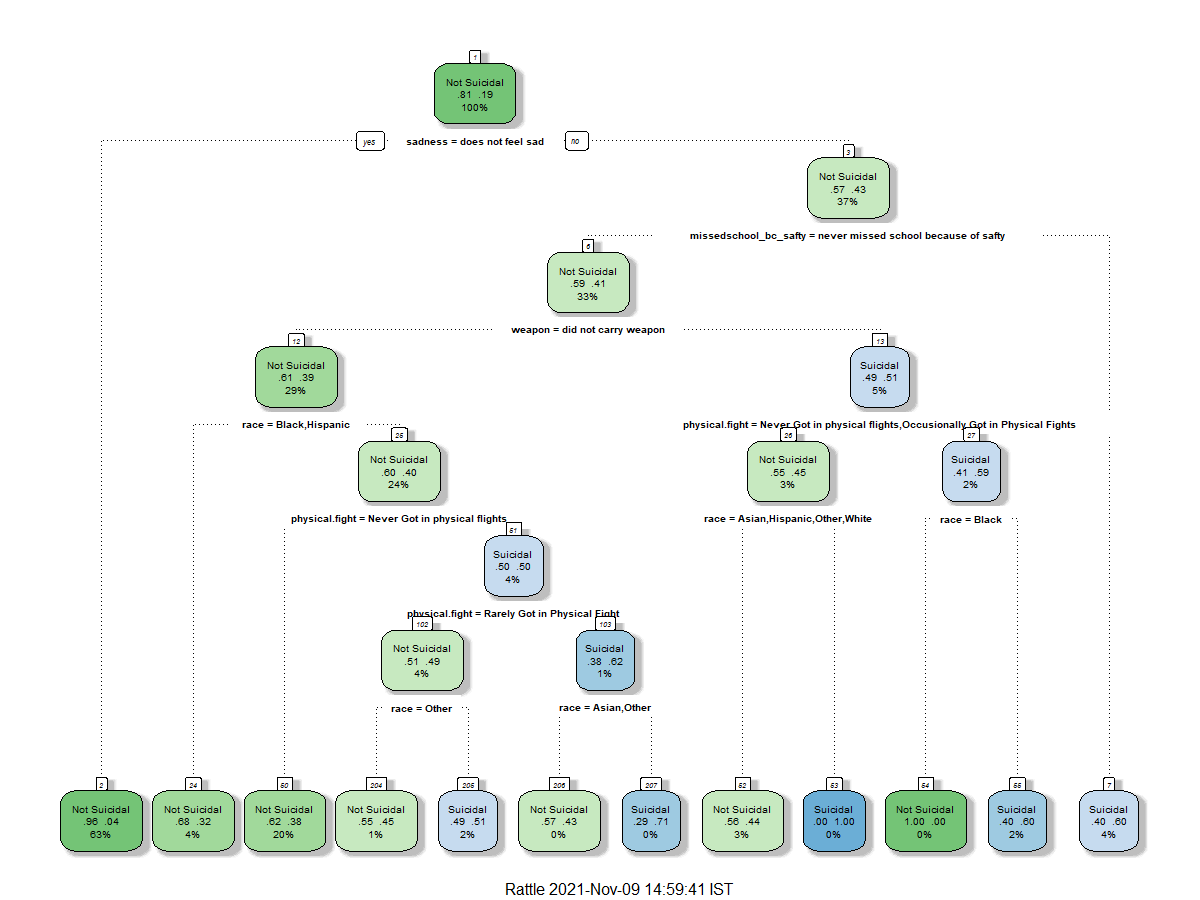
Figure 4b:Decision Tree 3
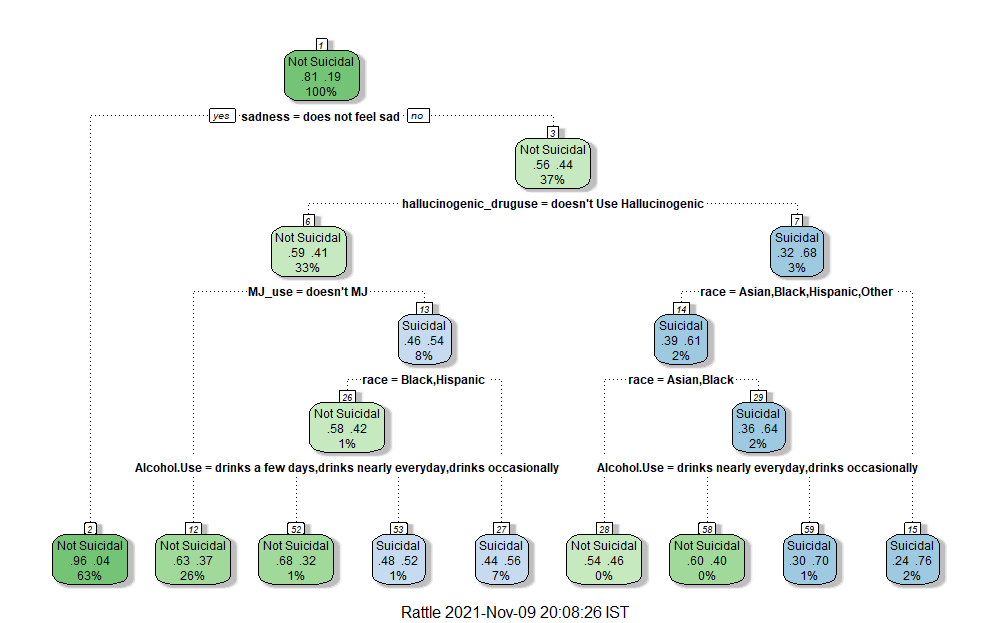
|
Also using the variable "considered attempting Suicide" as the root node, this decision tree looked at how different drug and alcohol use and race interact with whether one has considered suicide or not. This decision tree above tells us that whether someone is reports feelings of sadness or not is a great indicator if someone has considered attempting suicide or not. Of those who did not report sadness, the uses of hallucinogenic drugs is an important factor on whether one has considered attempting suicide or not. Of those who don't used hallucinogenic drugs the use of Marijuana is an important indicator. This decision tree, provided some evident to my hypothesis that drug and alcohol use is an important indicator of suicided risk factors.