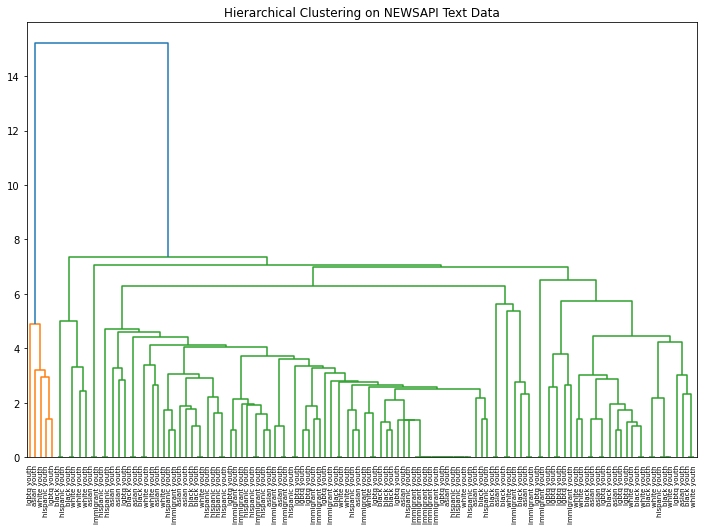
Clustering Record Data in R
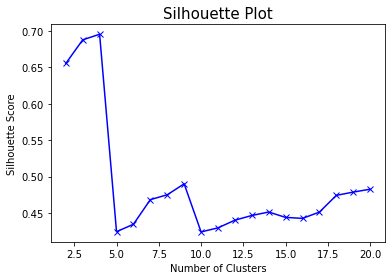
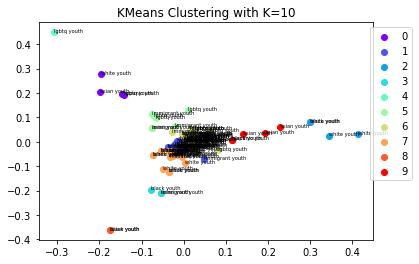
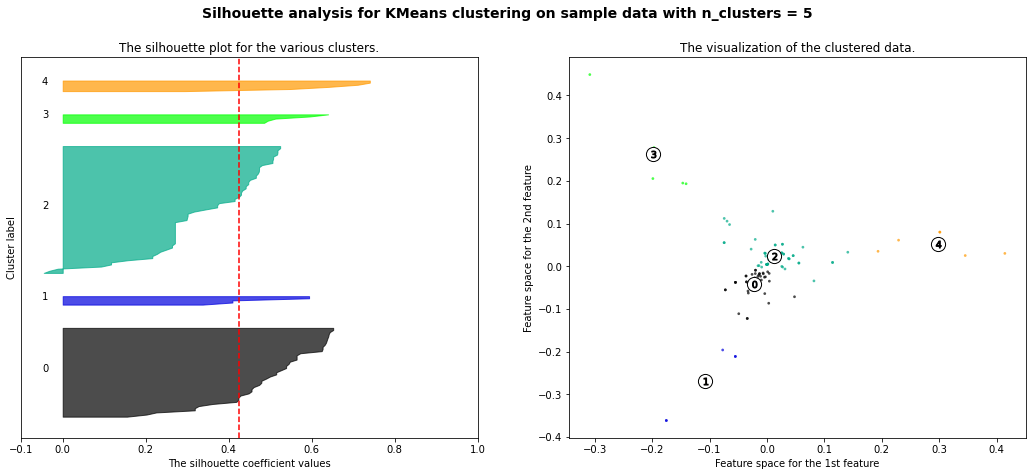
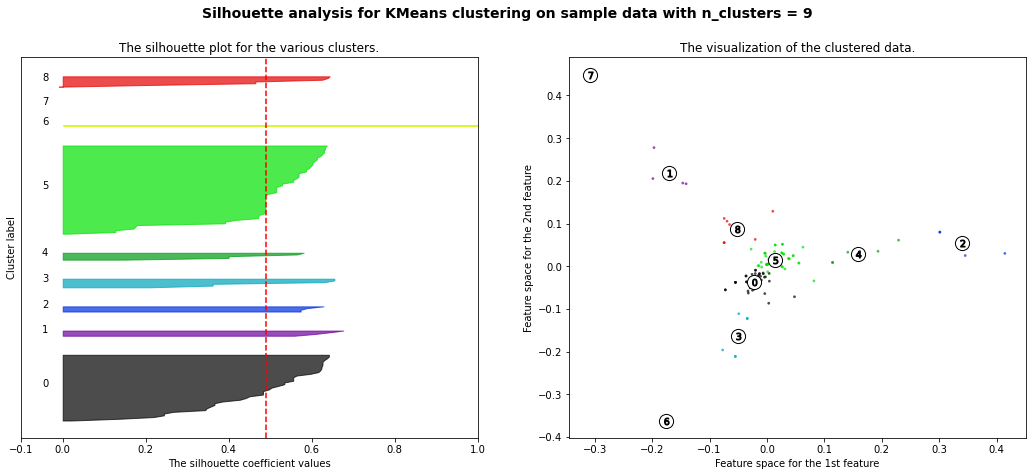
Clustering analysis was performed using the YRBSS dataset. The data contains categorical variables including gender, race, sexual orientation, whether one carries a weapon, whether one gets in physical fights, feelings of sadness, whether one has considered attempting suicide, whether one has made plans to attempt suicide, and more. All the labels were removed from the data to conduct clustering.Link to dataset & code: Clusterings dataset. R code used.
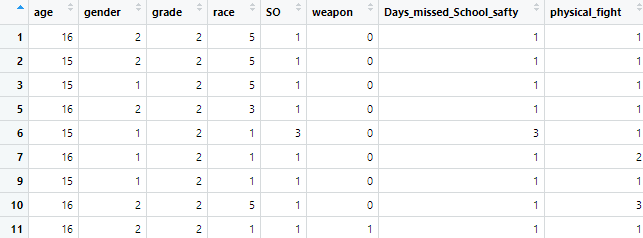
Figure 1a: Dataset Prior to Cleaning
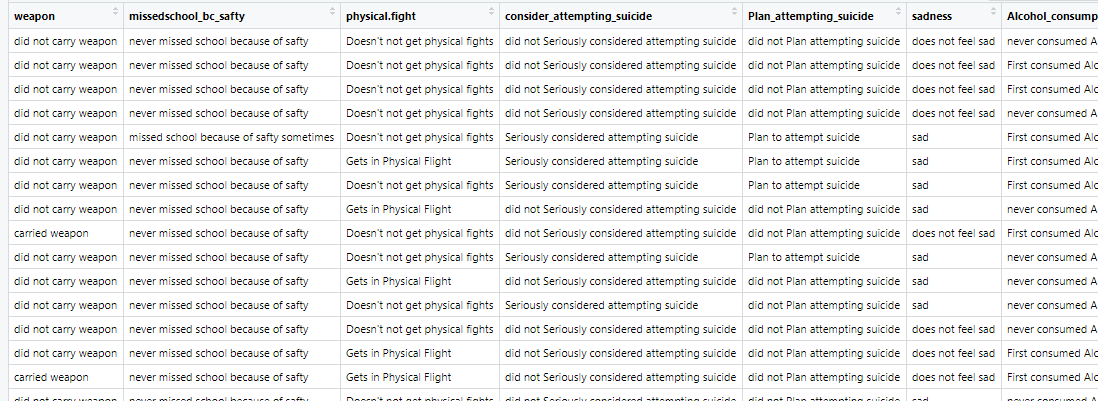
Figure 1b: Clean Dataset